Вступление
Графит (Graphite) — очень хороший сервис для работы с time series данными. Он он из коробки дает как интерфейс для отображения данных, так и api для сохранения данных. Однако мы практически не пользуемся ни первым ни вторым напрямую.
StasD — именно его мы используем для передачи данных т.к. он обеспечивает более качественное сохранение данных, которые приходят очень часто.
Графана (Grafana) — ее мы используем для отображения графиков. В ней можно создавать свои доски и панели и графики.
Почему очень важно правильно называть метрики
Метрики очень важно правильно называть из-за того, что правила при хранении и агрегации метрик зависят от их названий. См. ниже “Настройки“.
Основные правила
Окончание:
count — метрика заканчивается на count. Это счетчик плюс один. Агрегация через суммирование.
min/max/lower/sum — метрика заканчивается на него. Агрегация через соответствующую функцию.
gauge — метрика заканчивается на gauge или лежит внутри stats.gauges. Это текущее значение. Агрегация через average.
Правильно: регистраций за последние сутки. Запрашиваем метрику 24 раза в сутки. Храним как gauge
Да. При агрегации по правилу average через 90d останется только одна метрика со средним значением за сутки
Нет. derivative перестанет правильно работать т.к. будет сравнивать средние значения, а не текущее.
Неправильно: регистрации за последние сутки. Запрашиваем метрику 24 раза в сутки. Храним как count
Нет. При агрегации по правилу sum через 90d значения вырастут примерно в 24 раза.
Да. derivative будет правильно работать т.к. абсолютная разница между днями будет правильной.
Какое должно быть окончание:
Если это количество которому делается increment в коде, то это обязательно в конце count
Если это общая величина на момент получения, то в конце стоит gauge/average.
Ключ метрики состоит из параметров, которые разделяются между собой точками. Виртуально мы делим ключ на две части:
Основная или название метрики
Измерения или параметры метрики
Основная часть – это нечто с говорящим и понятным всем названием по которому легко понять к какому проекту какого контура, какой системе и какой библиотеке относится данная метрика.
Параметры или измерения – это вариативная часть метрики. Например деление счетчиков по стране или языку посетителя – это и есть параметры. Или таким же параметром является тип ошибки в метрики “ошибка”: database_connection, database_query, memcached_get, redis_set и т.д.
Если увидев пример с метрикой ошибки вам захотелось где-то поставить точку – вы на правильном пути. Важно понимать что графит и графана позволяют вам использовать например “*” между точками вместо конкретного ключа метрики. И отделив error.database.connection и error.database.query точками, а не подчеркиваниями мы можем построить график всех ошибок базы данных.
Очень важно: количество точек в метрике для одной метрики должно быть одинаковым. Нельзя сделать error.database.connection и оставить error.memcached_get т.к. в этом случае уже не получится так же легко построит график ВСЕХ ошибок без деления по сервисам. Можно, но не так удобно.
Отличный способ понять правильное ли дано имя – поставить вместо каждого параметра * и спросить себя имеет ли эта сумма какой-то реальный смысл? А если часть звездочек заменить на отдельное значение, тоже имеет реальный практический смысл, отличный от “все события подсистемы X”? Если да, то вы правильно выбрали имя и количество параметров для метрики.
Пример: у нас есть регистрации через разные соц. сети. Конечно есть параметр “тип регистрации”, который равен twitter, facebook и т.д. Есть стандартные измерения: у нас это язык, страна, является ли регистрация тестовой. И еще дополнительный параметр с какой формы/страницы это регистрация. Вроде все понятно. Везде ставим * получаем все регистрации. Указываем твиттер, главная, русский, * для страны, не тестовый и и получаем солько регистраций с главной через твиттер на русском языке из любой страны.
Вовремя остановиться
Тут конечно тоже важно не увлекаться с именами и иногда рабочая метрика, пусть с кривым названием, но сейчас лучше, чем с правильным, но через год. Потому что тут тоже возникает проблема: что первичнее?
Например есть метрика по социальным данным. Это просто person.count.
Потом захотелось понять сколько с фотографиями и появилась person.photos.count.
Потом появилось желание знать сколько людей с активным профилем, а сколько с неподтвержденным. Появилось person.status.{active|pending}.count. И вот в этот момент прозвенел первый звоночек. Вроде уже есть просто person.count и появился еще один, но с делением по статусам.
Потом появляется желание видеть сколько людей с Facebook регистрируется. Второй звоночек. И вроде такая метрика уже есть (см. предыдущий раздел), надо просто поставить все * и будет нужное число, но лучше сделать еще одну дублирующую метрику без всех этих параметров и измерений.
Так появляется person.linked.facebook.count.
И тут находится ошибка. Случайно. Оказывается, мы перестали загружать фотографию при регистрации через фейсбук.
Что делать? Нужна еще одна метрика, чтобы следить за динамикой. Cколько регистрируется через Facebook мы знаем, теперь надо понять сколько из них с фотографией.
Но куда разместить такую метрику внутрь person.linked.facebook или внутрь person.photo???
Ответ: не важно куда размещать. Важно чтобы метрика была и по ней был график и на него регулярно смотрели и название было говорящее.
Будет одинаково хорошо смотреться как person.linked.facebook.photo (или with_photo или даже facebook_with_photo), так и person.photos.facebook.count. Но если изначально было известно про такие требования, то конечно надо было делать person.type_{facebook|twitter}.{with_photo|without_photo}.count
Retention и настойки
Очень правильно указать retention с самого начала т.к. оказалось миграция whisper-resize некорректно обновляет старые интервалы по крайней мере в моем случае это выглядело как применение average вместо sum по счетчикам. В документации graphite.readthedocs.io говорится про необходимость указывать кратные значения. Например можно хранить с группировкой 60s и 300s, но нельзя 180s и 600s. Мои интервалы этому соответствуют 10s -> 1m -> 10m -> 30m -> 24h
Настройки:
Наши новые настройки следующие (актуально на понедельник 16 мая 2016):
# Schema definitions for Whisper files. Entries are scanned in order,
# and first match wins. This file is scanned for changes every 60 seconds.
#
# [name]
# pattern = regex
# retentions = timePerPoint:timeToStore, timePerPoint:timeToStore, ...
# Carbon's internal metrics. This entry should match what is specified in
# CARBON_METRIC_PREFIX and CARBON_METRIC_INTERVAL settings
[carbon]
pattern = ^carbon\.
retentions = 60:90d
[statsd]
pattern = ^statsd\.
retentions = 60:90d
[stats]
pattern = ^stats
retentions = 10s:1d, 1m:7d, 10m:30d, 30m:90d, 24h:5y
[default_1min_for_1day]
pattern = .*
retentions = 10s:1d, 1m:90d, 10m:1y
Наши новые настройки следующие (актуально на понедельник 16 мая 2016):
ВАЖНО: с 11 февраля 2020 пришлось выставить xFilesFactor = 0 для всех метрик, т.к. в редкособираемых данных были явные проблемы с метриками min/max/mean.
# Aggregation methods for whisper files. Entries are scanned in order,
# and first match wins. This file is scanned for changes every 60 seconds
#
# [name]
# pattern = <regex>
# xFilesFactor = <float between 0 and 1>
# aggregationMethod = <average|sum|last|max|min>
#
# name: Arbitrary unique name for the rule
# pattern: Regex pattern to match against the metric name
# xFilesFactor: Ratio of valid data points required for aggregation to the next retention to occur
# aggregationMethod: function to apply to data points for aggregation
#
[lower]
pattern = \.lower$
xFilesFactor = 0.1
aggregationMethod = min
[upper]
pattern = \.upper(_\d+)?$
xFilesFactor = 0.1
aggregationMethod = max
[min]
pattern = \.min$
xFilesFactor = 0.1
aggregationMethod = min
[max]
pattern = \.max$
xFilesFactor = 0.1
aggregationMethod = max
[sum]
pattern = \.sum(_\d+)?$
xFilesFactor = 0
aggregationMethod = sum
[count]
pattern = \.count(_\d+)?$
xFilesFactor = 0
aggregationMethod = sum
[gauge]
pattern = \.gauge$
xFilesFactor = 0
aggregationMethod = average
# vdm: для метрик, которые не соблюдают code-style, но лежат внутри gauge (например см. ng)
[gauge_stats]
pattern = ^stats\.gauges\.
xFilesFactor = 0
aggregationMethod = average
# vdm: все что связано со временем. Примерно до 2016-05-17 считалось неправильно по схеме sum вместо average
[stats_timers]
pattern = ^stats\.timers\.
xFilesFactor = 0
aggregationMethod = average
# vdm: классные метрики от statsd с разными плюшками
[count_legacy]
pattern = ^stats_counts\.
xFilesFactor = 0
aggregationMethod = sum
# vdm: самая последняя по умолчанию делает average
[default_average]
pattern = .*
xFilesFactor = 0
aggregationMethod = average
Чтобы результат применился для имеющихся метрик нужно явно вызывать см. полезные ссылки на эту тему:
ls -la /var/lib/storage/whisper/stats/timers/nginx/prod/response/phplogs/server_nye_wt_gw1/http/GET/200/time
sudo -i
whisper-set-aggregation-method.py /var/lib/storage/whisper/stats/timers/nginx/prod/response/phplogs/server_nye_wt_gw1/http/GET/200/time/mean.wsp average
whisper-resize.py /var/lib/storage/whisper/stats/timers/nginx/prod/response/phplogs/server_nye_wt_gw1/http/GET/200/time/mean.wsp 10s:1d 1m:7d 10m:30d 30m:90d 24h:5y
find ./ -type f -name '*.wsp' -exec whisper-resize.py --nobackup {} 10s:1h 10m:7d 24h:1y \;
# Нюансы
В режиме SingleStat надо обязательно задавать max data points иначе счетчик будет неправильным, если точек больше дефолтного значения. Я задаю 999999. Особенно это хорошо видно если много событий и задан диапазон довольно большой. Как вариант решения проблемы — это использование summarize который уменьшит количество точек.
Продолжение пункта 1. Если выставить группировку меньше 1 часа, а точек довольно много, то строка total может показывать значения неверно т.к. суммирует по точкам, а часть из них загружена не будет. В этом случае надо выставлять max data points побольше.
Если ставить sumSeries до summarize то данные будут неправильно группироваться. Очень хорошо видно если сравнивать 1w и 1d в summarize. Это следует из описания sumSeries. Похоже что на диапазонах меньше 1w это незаметно, скорее всего тут еще как-то примешивается retention и aggregation схемы.
Если смотришь time и там берешь count и используешь группировку summarize то обязательно его надо брать по avg. Нельзя делать sum. Если схлопывается несколько линий в одну, то нужно делать не sumGroup, а averageGroup.
Продолжение пункта 4. Если работаешь с time и берешь mean то нужно понимать, что при упаковке по времени будет использоваться average и к ней нельзя применять min, max в ожидании получить, например, min за неделю или max за неделю в summarize. Ты получишь одинаковые значения.
Если нужно выводить графики с редкими событиями, например, ошибки которых может и не быть, то нужно использовать функцию transformNull. Без этого current, например будет брать последнее значение, что неверно. В примере с ошибкой мы будем считать что ошибка все еще есть.
В виджете SingleStat если сделать Repeat на уровне виджета, а не row то не пдоставляются корректно значения параметра.
Если вы в настройках панелей решили включить Hide time info и активно пользуетесь Relative Time в них же, то для вас может оказаться сюрпризом, что при выборе в самом верху дашборда точных дат «от» и «до», эти настройки будут проигнорированы. Поэтому я всегда включаю их отображение.
# Стайл-гайд
1 | Если на графике выводится несколько линии и делаем Stacked, то обязательно использовать цветовое кодирование для облегчения понимания что перед нами с помощью:
| 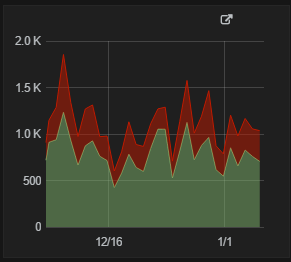 |
2 | Если график обычный, не Stacked, то рекомендуется использовать по умолчанию:
| 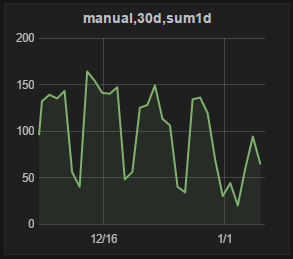 |
3 | Если нужно показать процент от чего-то, например график где регистрации через разные соц. сети и процент активаций, то это делаем тонкой белой линией с точками. Используются Series specific override:
| 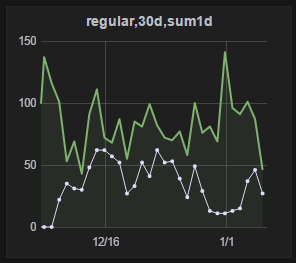 |
4 | Для сравнения с данными за прошлый период используем еле видный фон (применимо только для графиков типа из п. 2)
Важно: т.к. сравниваем даты в прошлом нужно учитывать агрегацию данных. Нельзя ставить для недели 1 минуту т.к. данные через 1 неделю доступны только с точностью 10 минут. | 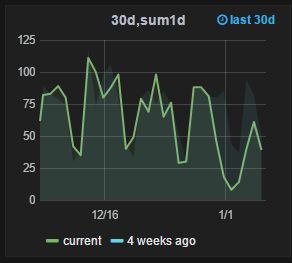 |
5 | При всех прочих равных используются следующие цвета:
| |
6 | Если есть множество разных линий и отдельный total то показать этот total:
| 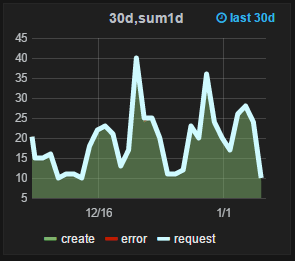 |
7 | Мониторинг. Количество событий за интервал времени (абсолютное значение) по count
К сожалению в этом случае график под числом получается формальный т.к. там и показаны те точки для которых сделан total. Гораздо интереснее было бы показывать больший интервал например 30d, внутри делать группировку по 1d и для него уже выводить current. Но в этом случае будут проблемы со значениями т.к. в 00:00 будет новый день и абсолютные значения станут очень маленькими. Но эта проблема решается если в функцию группировки через summarize передавать третий параметр true. Тогда можно использовать
| 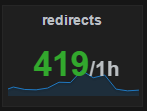 |
8 | Мониторинг. Проценты (относительные зачения)
Обязательно current т.к. иначе он будет брать в расчет все остальные точки. | 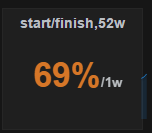 |
9 | Измерения. Для SingleStat делаем как Prefix с минимальным размером шрифта 20%. Если параметризация не поддерживается то используем символ “✖”. В противном случае указываем имя параметра. Такой подход дает при беглом взгляде на дашборд понимание что зависит от измерений, что нет, а в чем эти измерения уже учтены внутри. Подходит для общих измерений типа страна, язык и т.д. Обычные измерения специфичные для метрик по-прежнему используем в заголовке. | 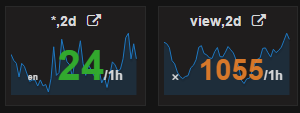 |
10 | Заголовки и интервалы. Используем интервалы 52w, 90d, 30d, 1d, 1h, группировка соответственно 1w, 1d, 1d, 30min, 10min. Они уходят в загловок например: registrations,52w,sum1w Для SingleStat другой набор стандартных интервалов. 30d, 2d, 6h и группировка соответственно 1d, 1h, 10min. В заголовок уходит только интервал, группировка указывается как описано выше внутри рядом с числом как /1h Если несколько разных интервалов стоит рядом, то порядок от большего к меньшему. Дополнительно возможны следующие суффиксы:
| 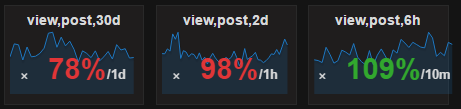 |
11 | Для вывода на одном графике изменений в течение интервала времени и коммулятивного графика используются следующие настройки. Линия count обычная линия. Линия total на другой оси и самым последним цветом:
Важнен порядок для первой линии:
Кстати этот вариант отлично подходит и для того чтобы первой была не одна линия, а несколько, в этом случае:
| 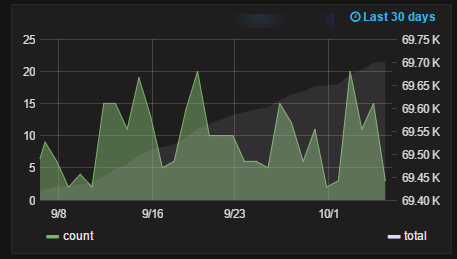 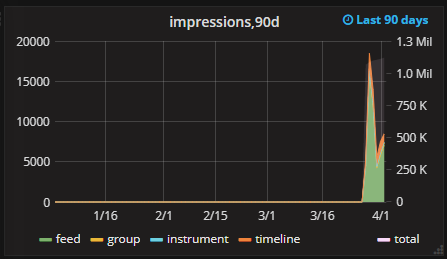 |
12 | Названия метрик которые передаются из Google Analytics Если нет segment – пишем all Если фильтр по адресу — и отдается основная страница то используем index | |
13 | График относительной величины в % Первый график скрываем Втором делаем asPercent(#A) в конце. |
Словарик
mean — то же самое что average
median — число которое делит выборку пополам — половина чисел меньше этого, половина чисел больше этого